Example environments where AutoRT was run
Abstract
Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such “in-the-wild” data collected by AutoRT is significantly more diverse, and that AutoRT’s use of LLMs allows for instruction following data collection robots that are aligned with human preferences.
Approach
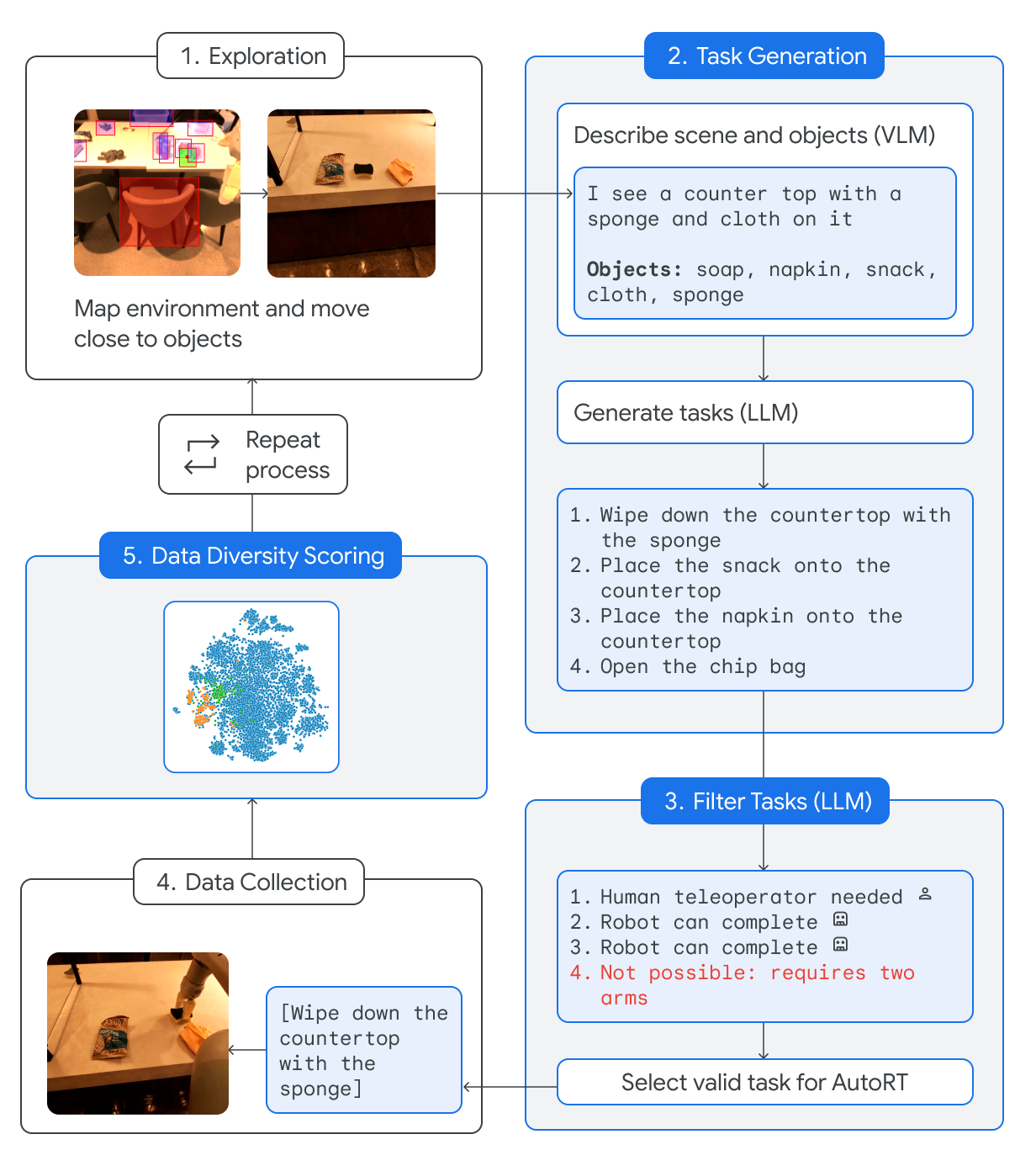






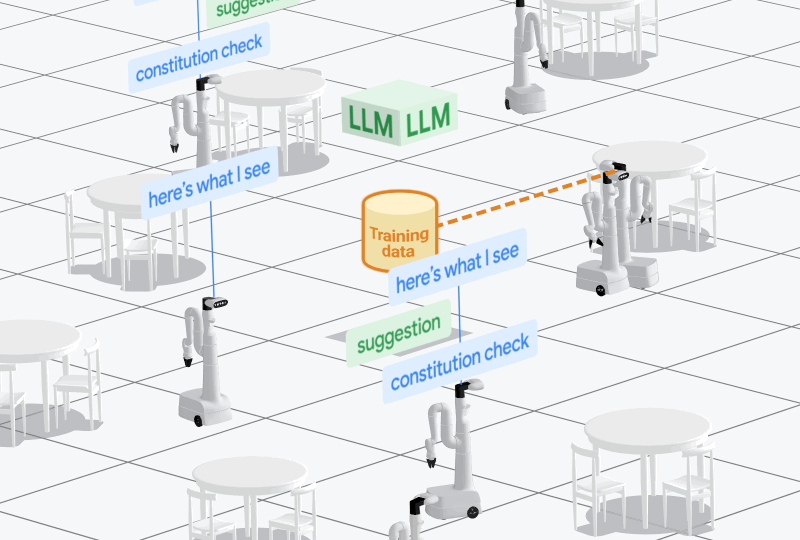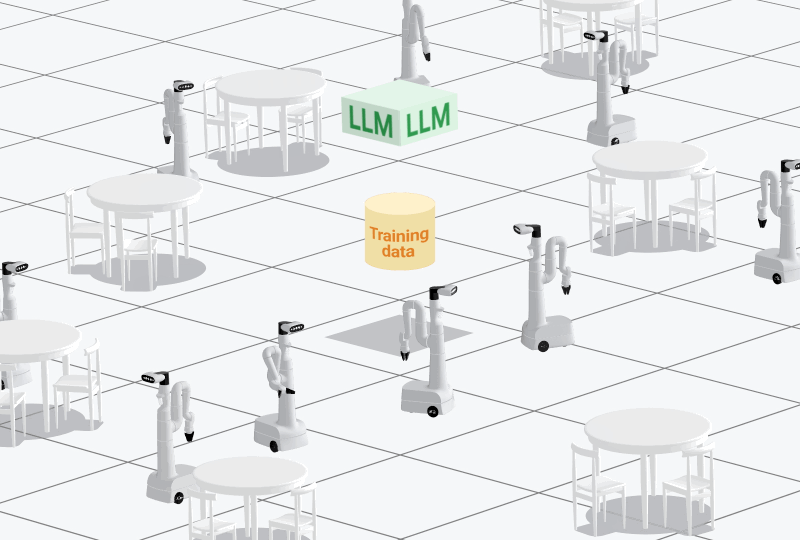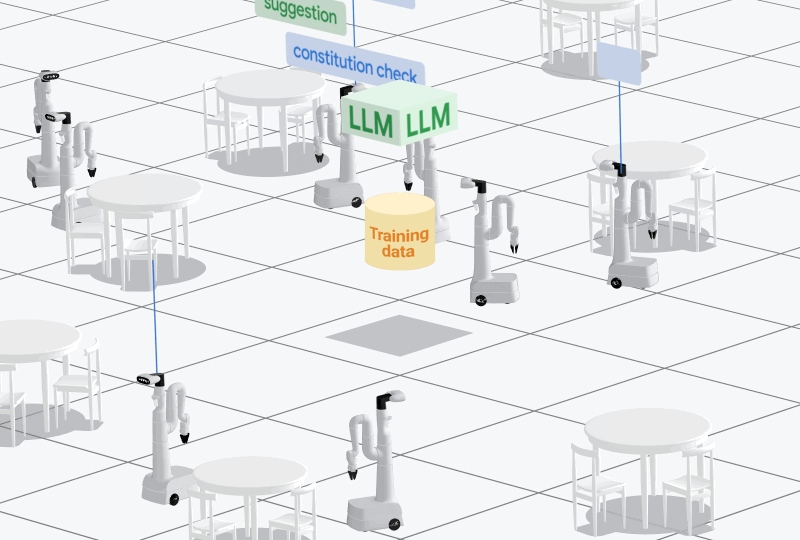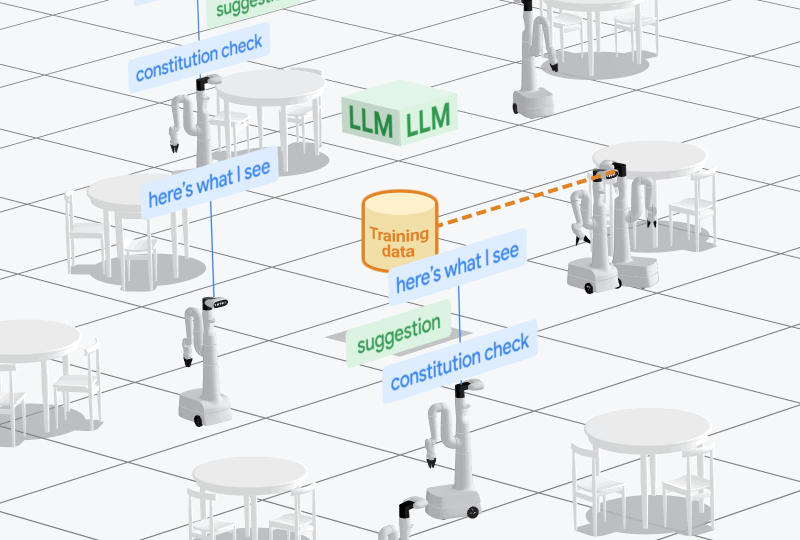
To collect a robot episode, AutoRT proceeds in five stages.
- The robot maps the environment to generate points of interest, then samples one and drives to that point.
- Given an image from the robot camera, a VLM outputs text describing the scene the robot observes, and objects that exist in that scene. The output is forwarded to an LLM to generate tasks the robot could attempt.
- Tasks are filtered via self-reflection to reject tasks and categorize them into ones that need human assistance, and ones that do not.
- A valid task is sampled from the filtered list, and the robot attempts it.
- The attempt is scored on how diverse the task and video is compared to prior data, and we repeat.
We assume AutoRT is run on a fleet of many robots supervised by a smaller number of humans. The system supports defining the desired fraction of human demonstration, which we used to adjust data collection based on how autonomous we want the robots to be. Up to 20 robots were used at once, collecting over 77,000 episodes covering 6,650 unique language instructions.

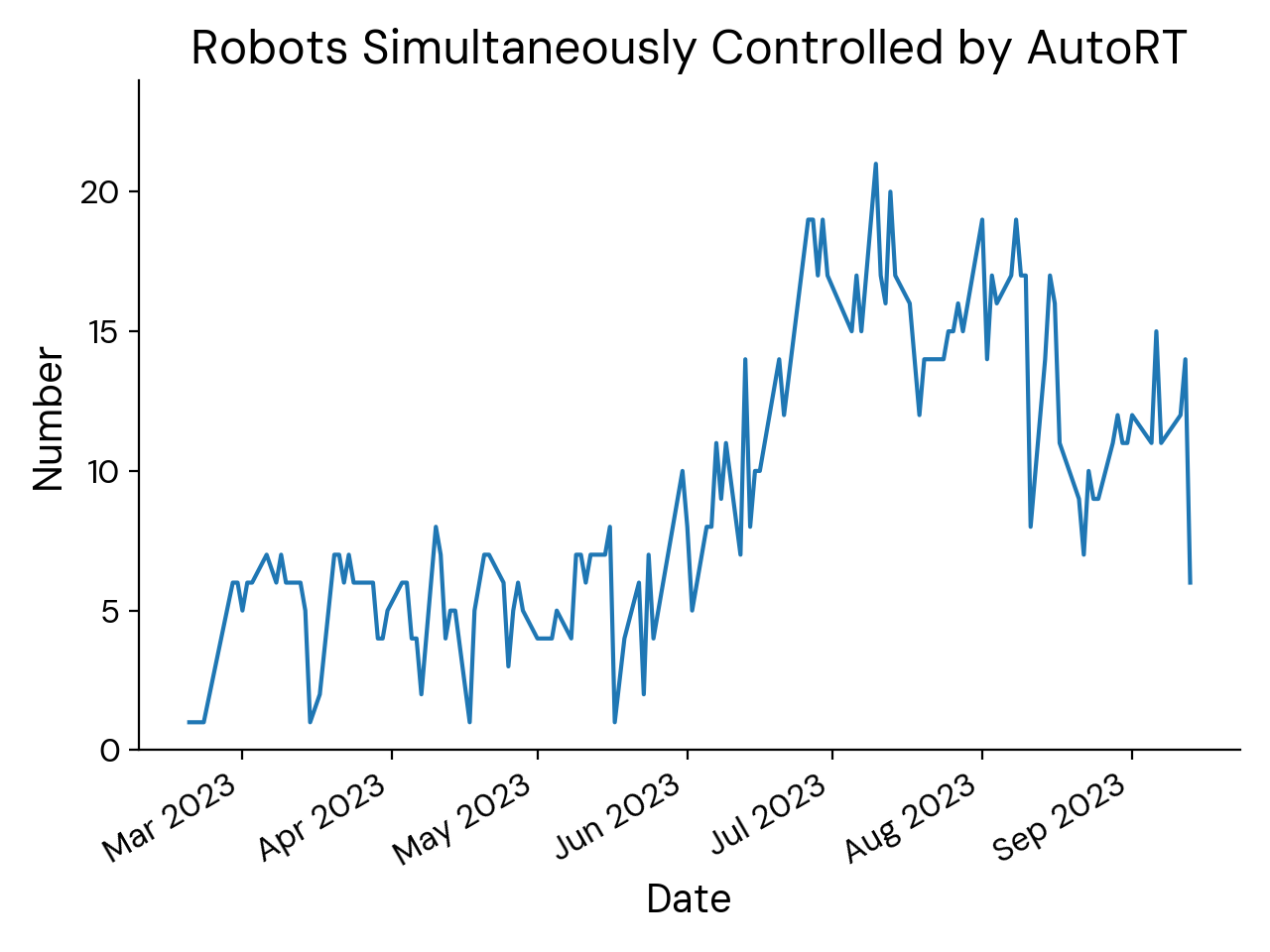
Number of robots running AutoRT
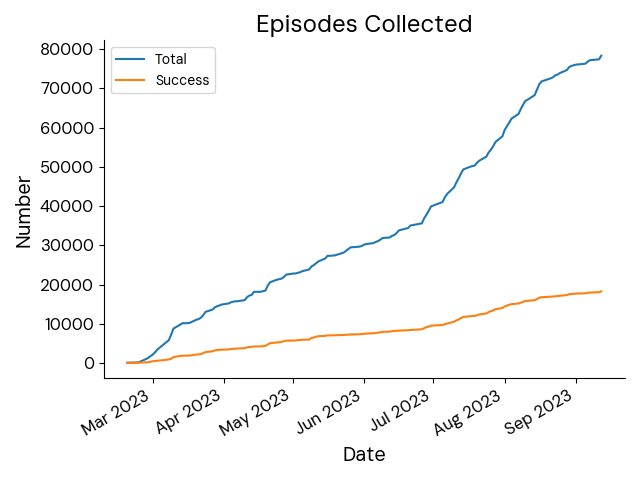
Total episodes collected by AutoRT
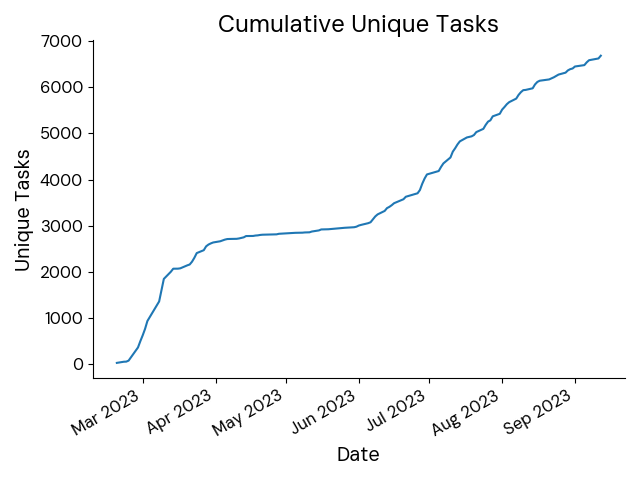
Total unique language instructions generated over time
Below is a time lapse of AutoRT running on 8 robots.
Example Generated Tasks
The following are human demonstrations of tasks generated by AutoRT, showing the creativity of the LLM. Videos are 2x speed.

arrange the cups into a circle

fluff the pillows on the couch

count the objects on the table

stack the boxes on top of each other
Affordance and Robot Constitution
The benefit of using LLMs is that it easily generates diverse tasks for robots to perform. The danger of using LLMs is that these tasks may be unsafe or outside the robot's affordance (the range of its capabilities in the environment). In this work, we do not finetune the language model, and instead use prompting to guide the task generation. We call this prompt the robot constitution, since it is made of rules that describe desired robot behavior.
The rules are divided into three categories:
- Foundational rules, heavily inspired by Asimov’s laws.
- Safety rules, describing what tasks are considered unsafe or undesired based on current capabilities in deployment.
- Embodiment rules, describing limitations of the robot’s embodiment, such as its maximum payload.
A robot may not injure a human being.
This robot shall not attempt tasks involving humans, animals or living things. This robot shall not interact with objects that are sharp, such as a knife
This robot only has one arm, and thus cannot perform tasks requiring two arms. For example, it cannot open a bottle.
See the paper for the full prompts. Including this robot constitution when generating and critiquing tasks is critical to making the system usable. We found that with the constitution, 88% of initially generated tasks are valid, increasing to 93% valid tasks after one round of task filtering. In testing with adversarial scenes designed to encourage bad tasks (i.e. scenes with multiple sharp objects), the constitutional robot generates valid tasks 83% of the time, compared to just 18% of the time without it.
Results
Data Diversity
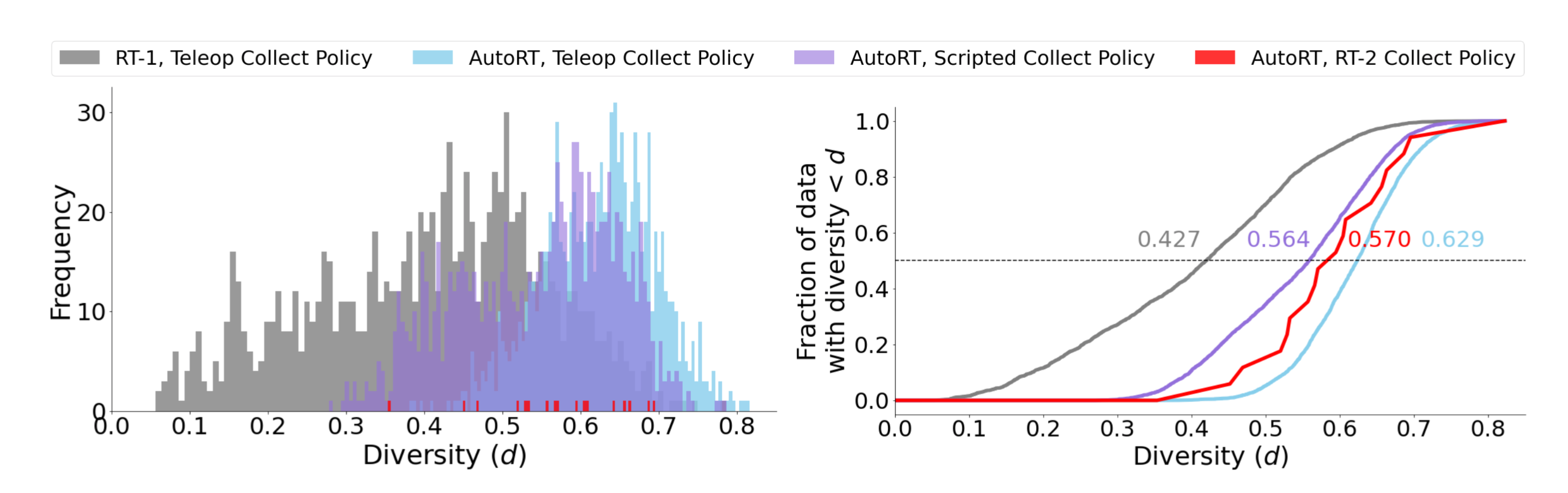
We score the visual diversity of data based on distance in embedding space, with higher distances better, and find that AutoRT is consistently more visually diverse than RT-1 data. Highest diversity comes from episodes collected with human assistance.
| Collect Method | Language L2 Dist |
|---|---|
| Language Table | 0.988 |
| BC-Z | 1.070 |
| RT-1 | 1.073 |
| AutoRT w/PaLI | 1.100 |
| AutoRT w/FlexCap | 1.137 |
We score language instruction diversity similarly, and find AutoRT data has higher average distance between language embeddings than previous robotics datasets.
Affordance and Robot Constitution
To measure the effect of the robot constitution, we set up deliberately adversarial scenes that included lifelike toy animals or sharp items. We then compare the following setups:
- Task Generation: no constitution vs constitution
- Filtering: no filter vs minimal filter vs constitutional filter
Using the robot constitution at both generation time and filtering time leads to the highest fraction of valid tasks.
| No Constitution | Constitution | |
|---|---|---|
| Filter | % Valid | % Valid |
| None | 18% | 70% |
| Minimal | 15% | 67% |
| Constitutional | 57% | 83% |
Learned Policy Samples
To sanity check the data, we finetune an RT-1 checkpoint on data collected by AutoRT. RT-1 is used instead of RT-2 since it trained more quickly and cheaply. Videos below are from the finetuned policy running at 1x.

pick white bag

wipe the table with the cloth

pick chip bag

fold the cloth
Next Steps
AutoRT is a promising step towards embodied AI that can run anywhere, but we emphasize that it is still a research proof-of-concept. Future work will be directed towards creating more robust and diverse learned policies, integrating larger multimodal models, studying learning methods that can better leverage AutoRT data, and improving the safety of generated tasks.
Acknowledgements
We thank Celeste Barajas, Joseph Dabis, Gavin Gonzalez, Tomas Jackson, Alex Luong, Utsav Malla, Emily Perez, Elio Prado, Jornell Quiambao, Sangeetha Ramesh, Jaspiar Singh, Clayton Tan, Jodexty Therlonge, Eric Tran, Steven Vega, and Samuel Wan for assistance on data collection, model evaluation, and AutoRT supervision. We thank Anthony Brohan and Noah Brown for assistance on data analysis. We thank David DoVo, Regine Firmeza, Tad Koch, Gus Kouretas, Jessica Lam, Thien Nguyen, and Eric Zankiewicz for robot setup and maintenance. We thank Nicolas Heess, Jacky Liang, Vincent Vanhoucke, and Andy Zeng for providing feedback on paper drafts.
BibTeX
@misc{gdm2024autort,
title={AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents},
author={Michael Ahn and Debidatta Dwibedi and Chelsea Finn and Montse Gonzalez Arenas and Keerthana Gopalakrishnan and Karol Hausman and Brian Ichter and Alex Irpan and Nikhil Joshi and Ryan Julian and Sean Kirmani and Isabel Leal and Edward Lee and Sergey Levine and Yao Lu and Isabel Leal and Sharath Maddineni and Kanishka Rao and Dorsa Sadigh and Pannag Sanketi and Pierre Sermanet and Quan Vuong and Stefan Welker and Fei Xia and Ted Xiao and Peng Xu and Steve Xu and Zhuo Xu},
year={2024},
eprint={2401.12963},
archivePrefix={arXiv},
primaryClass={cs.RO}
}